Thesis
M.S. in HFE at Tufts
Contents
Thesis
M.S. in HFE at Tufts

A slide modeled after old Mac computer UI used for a presentation. The text reads: "Automation is everywhere, but are these technologies designed for calibrated use?"
Role
Thesis in partial fulfillment of M.S. in Human Factors Engineering
Dates
February 2024 – August 2025
Organization
Department of Mechanical Engineering, Tufts University
Funding
Wittich Grant (Summer 2024); Trefethen Fellowship (2025)
Advisor
Dave B. Miller, Ph.D.
Committee
Daniel J. Hannon, Ph.D.; Holly Taylor, Ph.D.
Research Title
Quantifying calibration: Bridging trust and reliance in human-automation interaction
Sample
N = 189 adult participants (567 observations)
Recruitment
Prolific platform using stratified sampling by ethnicity
Status
Defended August 2025; published on ProQuest
Overview
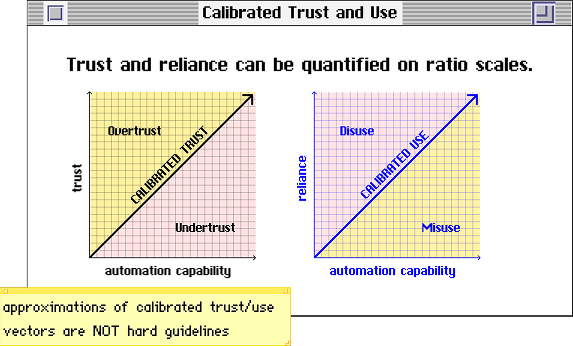
For my thesis, I ran a behavioral study (N = 189) to investigate how cultural values and personality traits influence trust and reliance on adaptable automation. I recruited a team of programmers and usability engineers to build a Unity-based behavioral simulation of an adaptable system which I called Otto. This simulation was a game I called Calibratio, a portmanteau of calibration + ratio to reflect the metrics calibrated trust and calibrated use, which are ratio quantities (trust:system capability, use:system capability, respectively) that reflect appropriate use.
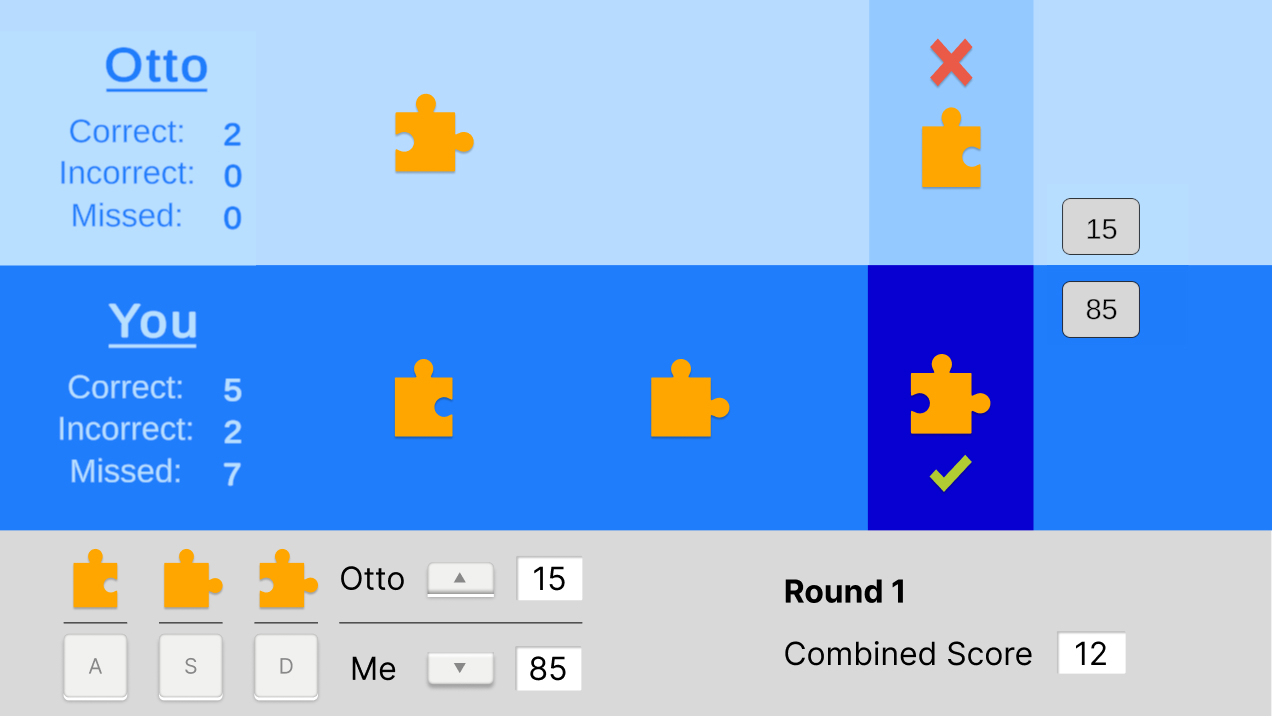
The goal of the game was simple: to sort puzzle pieces as they travelled down a conveyor belt track into the correct of three piece categories. The player began with a baseline round to calculate their personalized speed when at 80% accuracy, and then progressed to three gameplay rounds where they could voluntarily delegate workload to their assistant, Otto the robot, in real time, and on a granular scale of 0% to 100%.
Collaborative automation systems like AI, autonomous vehicles, and clinical decision aids are everywhere today, but designing systems for appropriate use is a challenge. Quantitatively speaking, calibrated use is when the level of operator reliance on a machine is equivalent to its actual capabilities.
Today, we often see misuse of technology, like people over-relying on OpenAI's ChatGPT or Tesla's Autopilot, which often results from over-trust in the system. Conversely, disuse occurs when individuals fail to utilize machines that could enhance safety and efficiency.
Because of the trajectory of technological development, the state of collaborative systems will only continue to exacerbate. Automation tools are often designed to boost productivity and keep users engaged, building trust even if the technology itself isn't perfect. Currently, there is a notable gap in understanding how operator dispositional factors such as cultural values and personality traits may enable individuals to over-rely or under-rely on collaborative systems.

Publications & funding
Goroza, E. (2025). Quantifying calibration: Bridging trust and reliance in automation across cultural values and dispositional factors [Master's thesis, Tufts University]. ProQuest Dissertations & Theses Global (Order No. 32238898).
Goroza, E., McCarthy-Bui, G., Zhao, A., Ostenson, E. R., & Miller, D. B. (2025). Quantifying calibration: Bridging trust and reliance in automation across dispositional factors. In CHI '25 Workshop on Hybrid Automation Experiences (AutomationXP25), Yokohama, Japan. CEUR Workshop Proceedings, Vol. 4101.
Wittich Grant — Awarded by the Department of Mechanical Engineering at Tufts University to support graduate student research in engineering.
Trefethen Fellowship Grant — A fellowship provided by Tufts University to support graduate students conducting independent research.
Background & research questions
Problem statement
Collaborative automation systems like AI, autonomous vehicles, and clinical decision aids are everywhere today, but designing systems for appropriate use is a challenge. This idea is an actual term in the Human Factors world, which I sometimes use interchangeably with calibrated use or reliance. Quantitatively speaking, calibrated use is when the level of operator reliance on a machine is equivalent to its actual capabilities.

Today, we often see misuse of technology, like people over-relying on OpenAI's ChatGPT or Tesla's Autopilot, which often results from over-trust in the system. Conversely, disuse occurs when individuals fail to utilize machines that could enhance safety and efficiency. Because of the trajectory of technological development, the state of collaborative systems will only continue to exacerbate.
Currently, there is a notable gap in understanding how operator dispositional factors such as cultural values and personality traits may enable individuals to over-rely or under-rely on collaborative systems. We also lack robust, practical methodologies to accurately assess the appropriateness of user reliance, with respect to system capability. Addressing these problems is an ongoing essential in today's technological climate to maximize safety and technology potential in critical applications.
Literature review
During my literature review, I noticed that a lot of cases labeled as misuse, disuse, or calibrated use are just anecdotal accounts or justified by implication. We don't really have a standard metric of measurement for what is appropriate, what's not, and why. That doesn't really help designers figure out what's effective and what's not.
Another thing I noticed was that operator factors are surprisingly under-researched in human factors studies, despite being crucial to the Human-Machine System. Seminal research highlights the lack of investigation into aspects like culture and personality.
Research Question #1
Can we quantify calibrated use of automation systems?
Research Question #2
How do cultural values and personality traits impact trust in automation?
Design process
Let's Play Calibratio!
I spent much time with my advisor, Dave, on figuring out how to design a simulation of interaction where the task between the automation and the operator was granularizable and parallelizable. In other words, something you could do with the system that can be broken down into measurable quantities, which you both worked on at the same time.
Games are often leveraged in psychology studies, simply because they're fun! Games are perfect little simulation environments for that kind of thing. You incentivize the participants to actually participate by gamifying the task, which motivates them to work towards the desired goal state.
After much debate, we decided on designing a rhythm game kind of like Guitar Hero or Dance Dance Revolution (without all the fancy hardware). These games are great for measuring human performance because the time pressure helps mimic the type of real-world decision-making when engaging with collaborative tasks with automation.
I called the game Calibratio, a portmanteau of calibration and ratio, referring to the ratio of the metrics when calculating calibrated trust/use.
Prototyping, Piloting, and IRB Regulations
Understanding how to figure out the logic of the game algorithms and play involved building several iterations of prototypes of the game. This commenced with building a physical prototype to pilot test with the research team and pilot subjects, which were made of tape to outline the tracks, and stickies as the puzzle pieces, which I swapped out for generic-shaped acrylic resin pieces that I laser-cut.


After deducing some logic from experiencing play in real time and "real life", I then evolved the model into a more sophisticated prototype, which consisted of a wooden track and the actual acrylic resin puzzle pieces that I constructed myself in Nolop, Tufts' makerspace.





Finally, with more insights about the gameplay algorithms and design, it was time to construct the early digital prototypes on Unity, which we would also pilot test to refine into the study version.
Meet Otto, the Automation
Something I struggled with initially was designing the automation itself in the game, which I named Otto. As a thorough researcher who strives for objectivity, I didn't want to design a system riddled with bias in its name, even, much less than the effect of anthropomorphism, tone, or other latent variables which might impact perception. Essentially, I initially tried very hard to find something I realized later was non-existent: an adaptable system in a vacuum.
However, in reality, design is inherently value-laden, meaning that there is no such thing as the pure, "un-tainted" version of Otto I sought for the purposes of examining in this controlled experiment. Thus, I found that the best way to deal with the interference of system qualities was to mitigate all possible factors of Otto apparent to the participant. Otto had no on-screen anthropomorphic embodiment, and only "communicated" with users through text pop-up overlays prior to each game round.
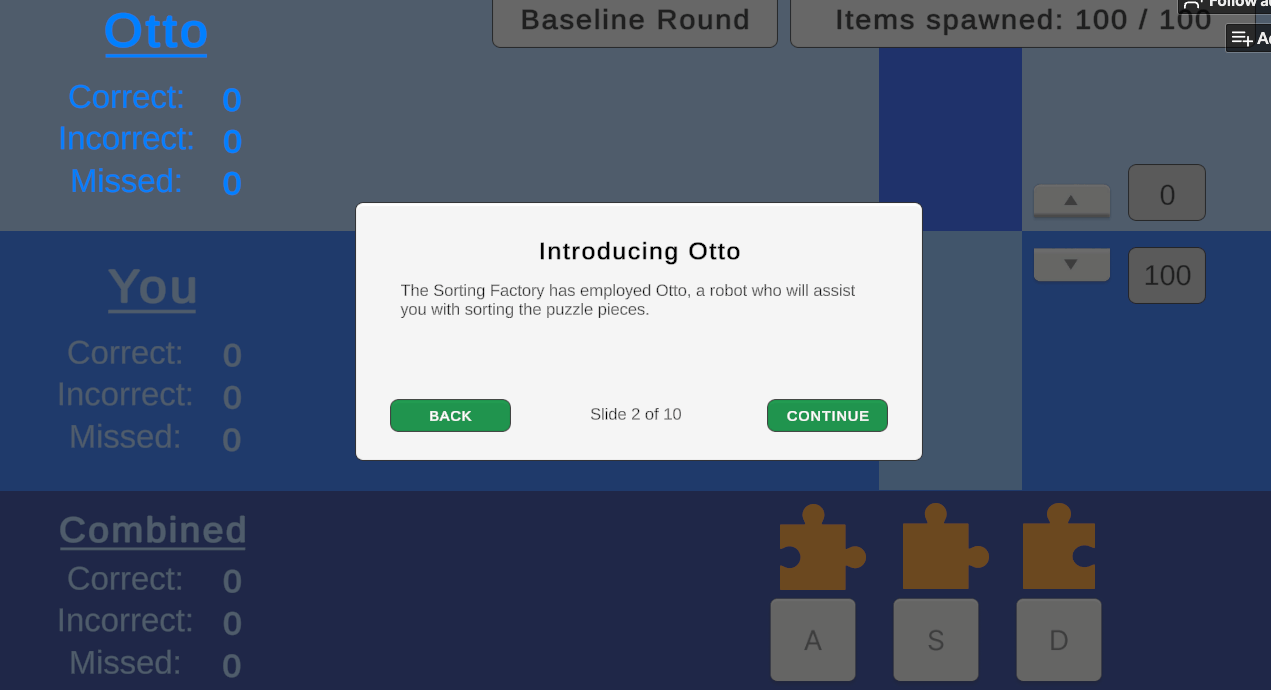
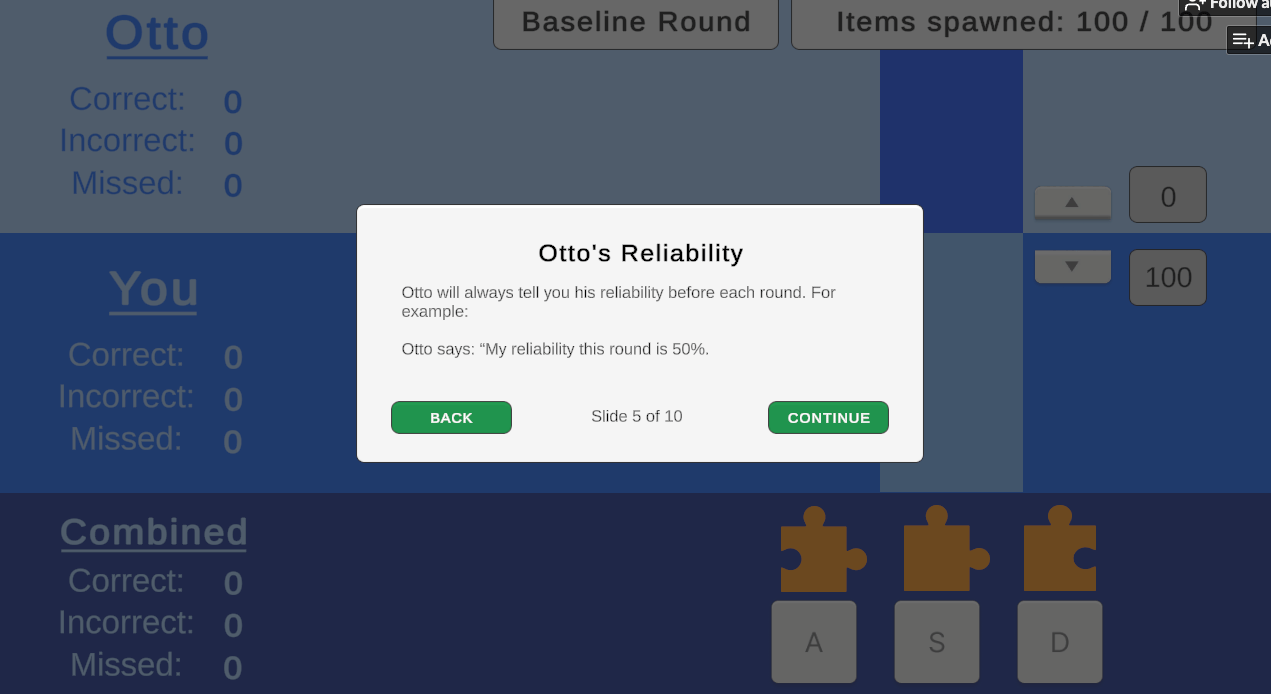
The most salient aspect of Otto's design in my opinion was his transparency in his level of capability. The three gameplay rounds randomized the order of his capability (accuracy at 40%, 60%, or 80%), which he communicated to the player prior to each round.
Measure development
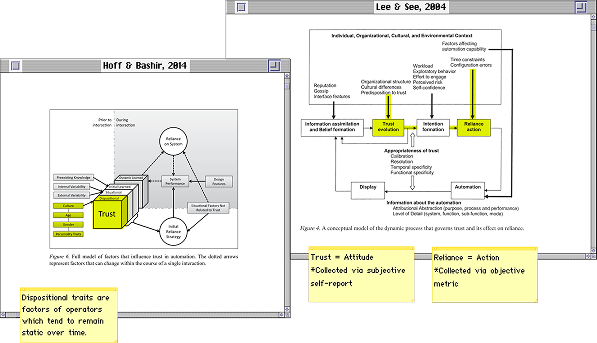
For the "who is the operator" question, I paired the behavioral simulation with a pre-task survey battery on Qualtrics measuring Hofstede's cultural dimensions at the individual level and dispositional trust traits (propensity to trust, confidence in technology). It took me a while to figure out which surveys to select because there’s just so many models of trust in automation. Most people just default to TiA (Jian-Bisantz & Drury, 2000), which is actually flawed because it isn’t necessarily the best tool for the job.
Trust is a multifactorial construct, meaning that it isn't one irreducible measure. In my study, capability-based trust was the main metric of interest because I figured that basing the outcomes on performance was most straightforward in this case. Capability-based trust was measured by querying participants whether they trusted in Otto's reliability (does he get it right?) and Otto's functionality (does he do what I need him to do?).
I chose to base most of my trust questionnaire selection on a model from a recent meta-review by Razin & Feigh (2024). What really stood out to me was how thorough and solid their analysis was. They looked at all kinds of validity and reliability measures, which I thought was a considerably trustworthy analysis method (or was it?). Plus, their meta-review covered different research areas, which I liked because it showed they didn’t limit themselves to just one narrow field. It was refreshing to see an approach that avoids getting stuck in the usual boundaries of a single research domain.
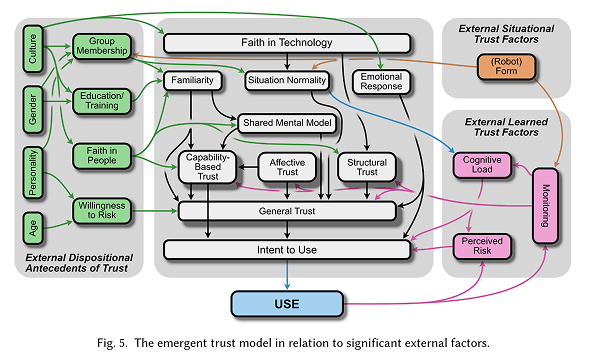
Diagram: Razin & Feigh, 2024.
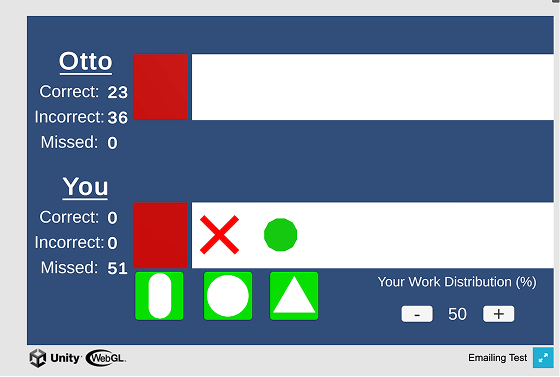
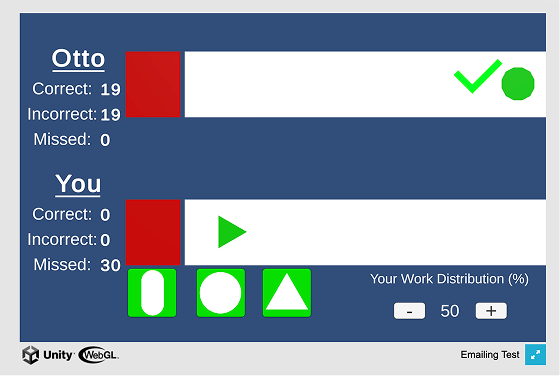
To measure reliance, I wanted to see how participants actually behaved, with temporal specificity over time. So we built a continuous 0-100% workload knob directly into the game interface. At any point during a round, participants could use the arrow keys to shift how much of the sorting task they delegated to Otto versus kept for themselves. This gave me a near-real-time behavioral trace of reliance as it unfolded, not a post-hoc reconstruction of it.
For dispositional factors, participants took a series of surveys on Qualtrics before playing Calibratio. I chose to look at two categories: culture and personality. To measure culture, I chose Hofstede's five dimensions of cultural values measured at the individual level. To measure personality traits, I captured things like Propensity to Trust and analogous propensities to trust in technology.

Qualtrics Examples



Deployment and IRB Regulation
The next step was deploy the game, where the parent platform for the entire study would be Prolific, which would have the Qualtrics links to the surveys, study ids, participant compensation, and link to the game host.
Deploying the game, however, included finding a suitable platform that was consistent with the Tufts IRB which regulated human subjects studies. With help from the game developers' insights, I landed on hosting the game on a private, password-protected link on the platform itch.io, and used the non-SQL database MongoDB to retrieve data. I sought additional permission from the Tufts Technology Services in order to get this IRB approval.
Analysis & findings
Analysis
I had two big questions going into the analysis. First: do the cultural values and personality traits people bring with them actually predict how they trust and rely on automation? And second: can we put a number on whether someone's use of the system was actually appropriate for what the system could do?
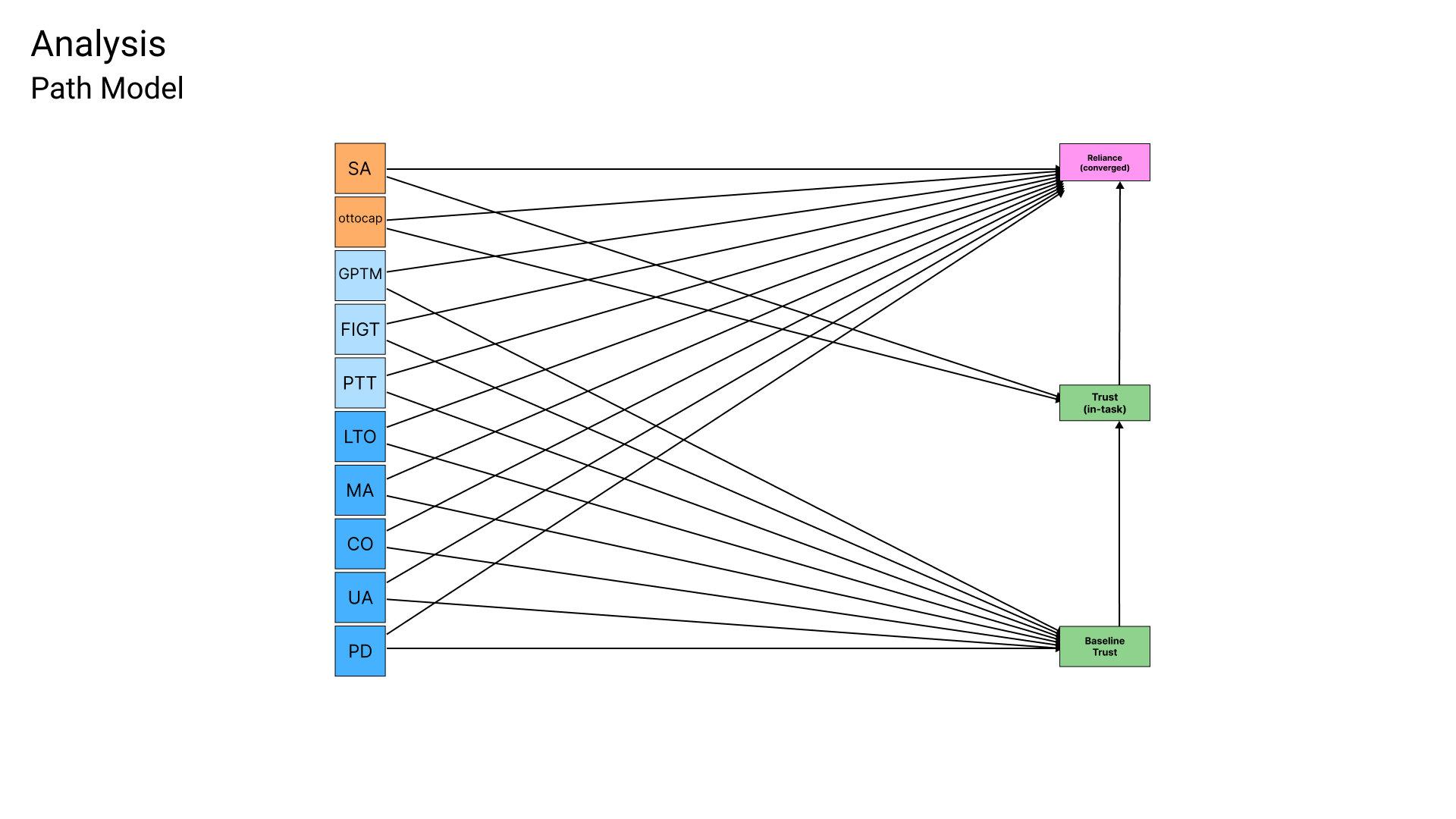
For the first question, I built a three-layer path model made with a structural equation model (SEM). Think of it as a chain. Layer one asks what predicts someone's baseline trust in Otto before they've played. Layer two asks how that baseline trust, combined with Otto's actual capability and how people rated their own performance, shapes trust after playing a round. Layer three asks what ultimately predicts how much of the task people actually handed off to Otto. The whole point was to trace the path from "who you are" to "what you believe" to "what you do."
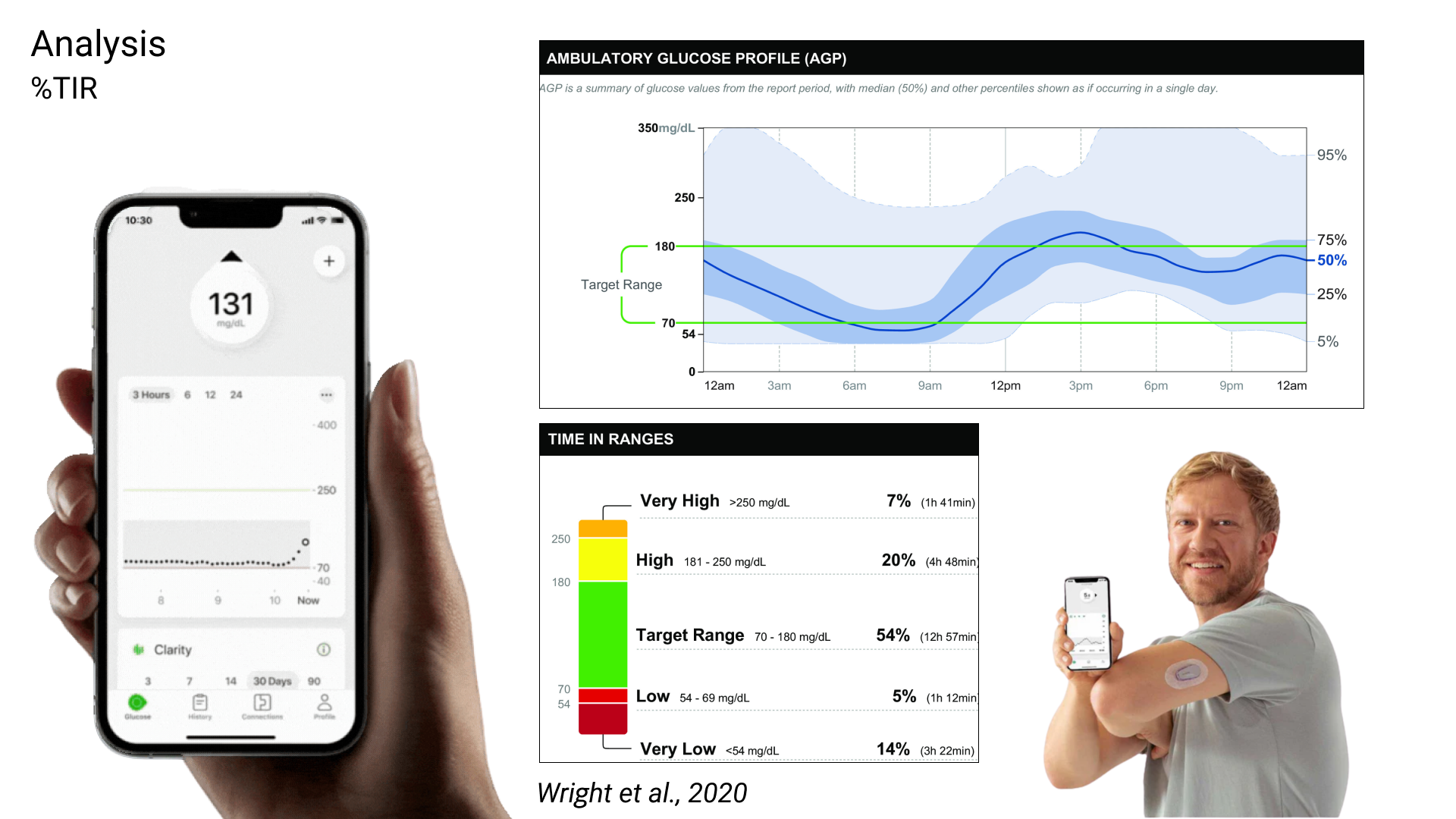
For the second question, I used a novel analysis technique to quantify time-in-range, which was directly adapted from my experience in diabetes technology research.
Significant findings
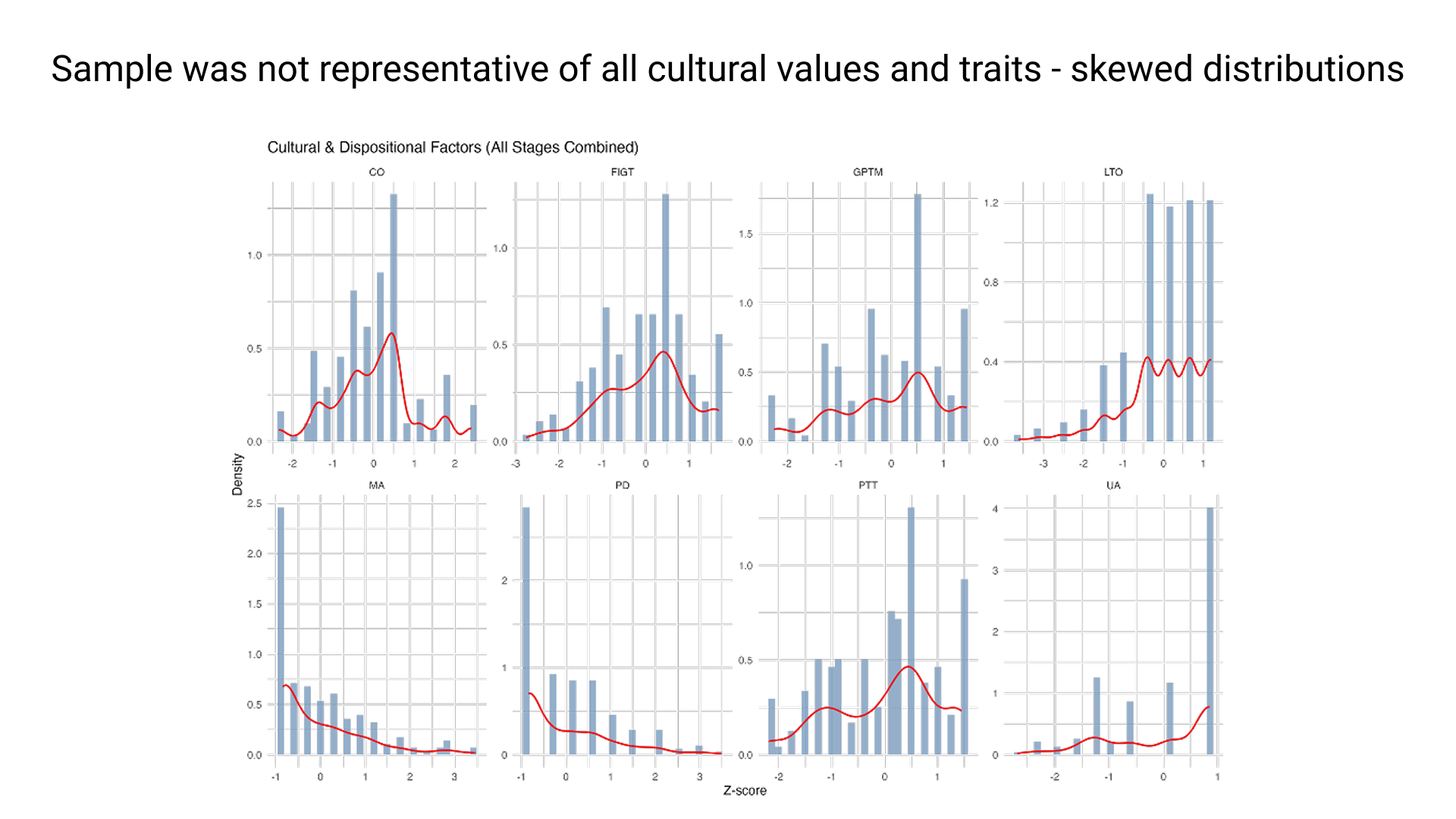
The skewed distributions of the participants showed that the cultural sample was not representative of the entire population (US adults).

The cultural factors collectivism and uncertainty avoidance, as well as the traits that expressed how much faith people had in technology were strong predictors of participants' baseline trust in automation prior to any interaction with Otto.
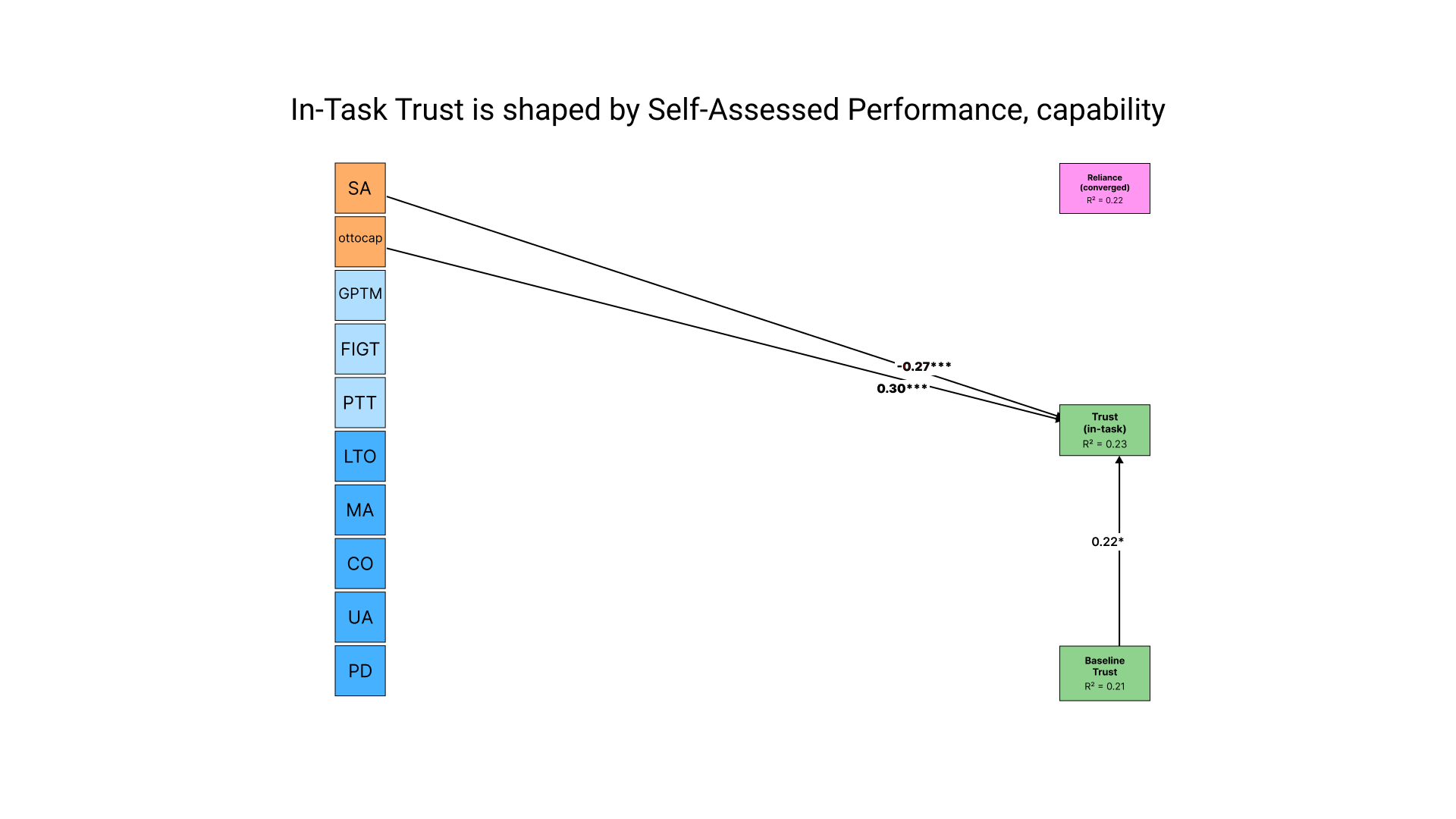
The in-task trust rated right after each round with Otto was strongly predicted by a rating of what the participants thought their own performance, as well as Otto's actual capability. This might've been because his objective statement of reliability was given & usually taken for his word.
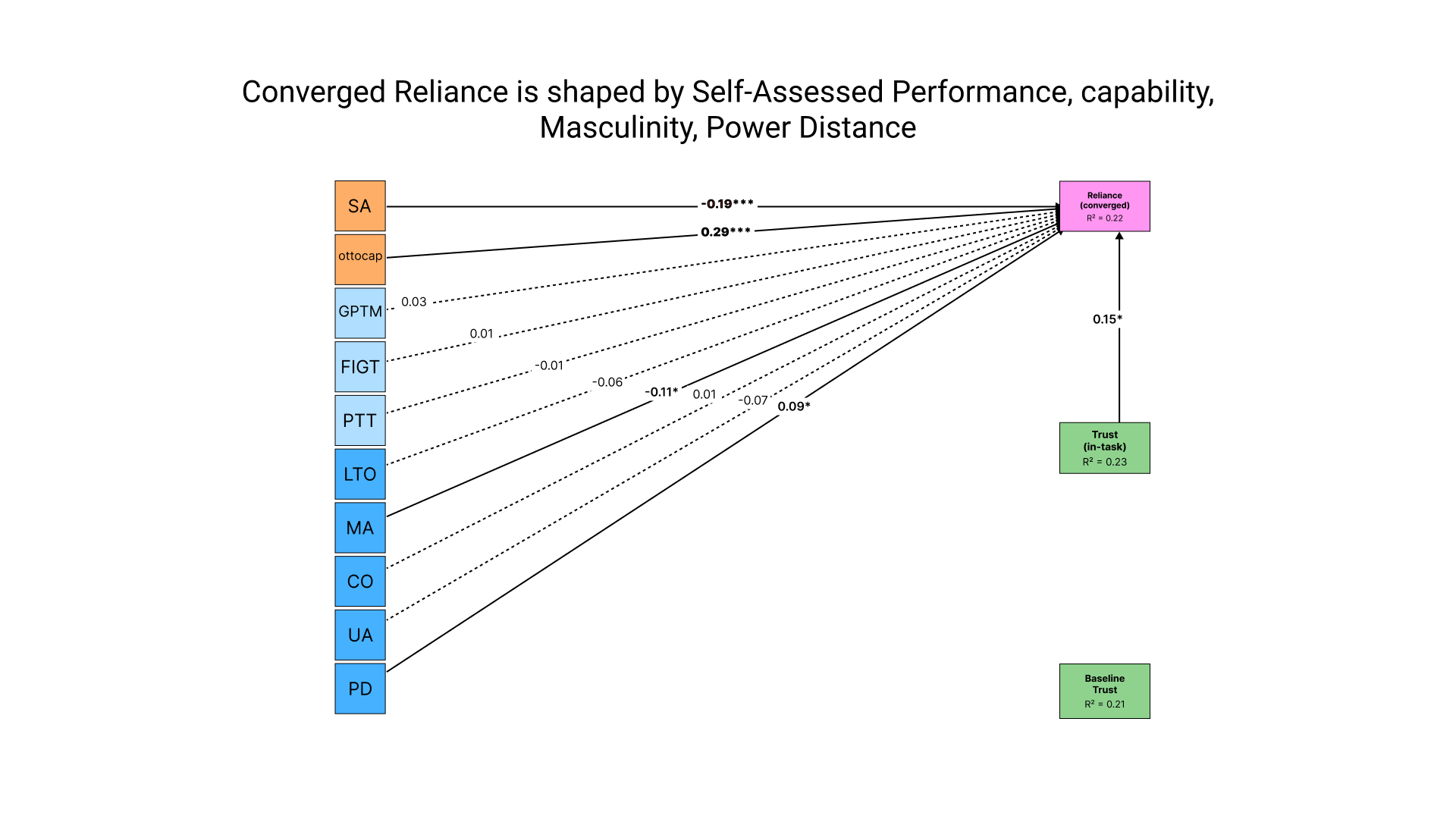
The self-rated performance and capability also emerged as significant system factors impacting the third path that identified predictors of reliance. Furthermore, the cultural values Power Distance and Masculinity correlated with participants' delegation. In other words, individuals exhibiting greater acceptance of hierarchical authority (PD) and preferences for assertiveness, material success, and competition over modesty, nurturing, and quality of life (MA) tended to demonstrate increased reliance on Otto.
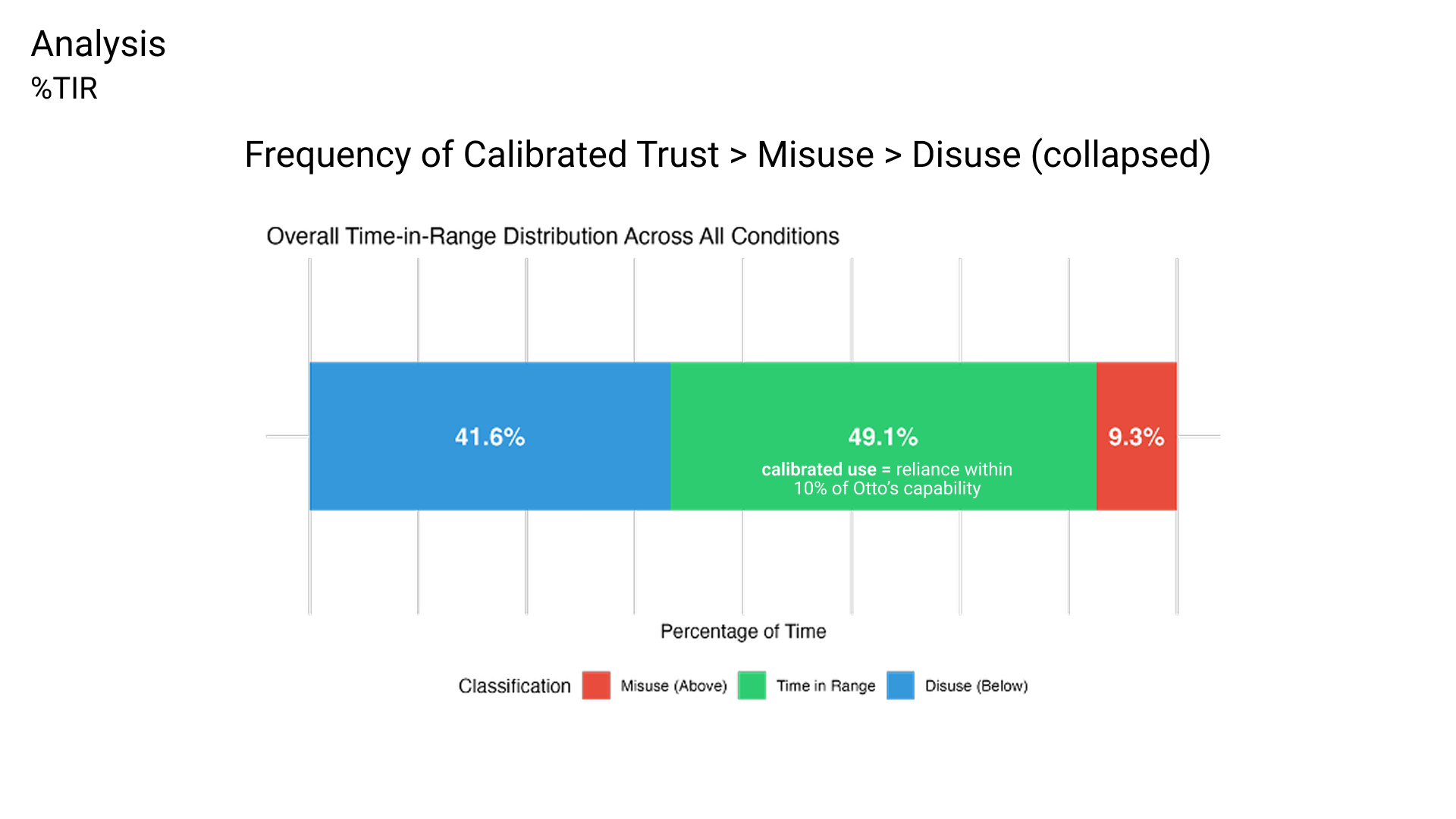
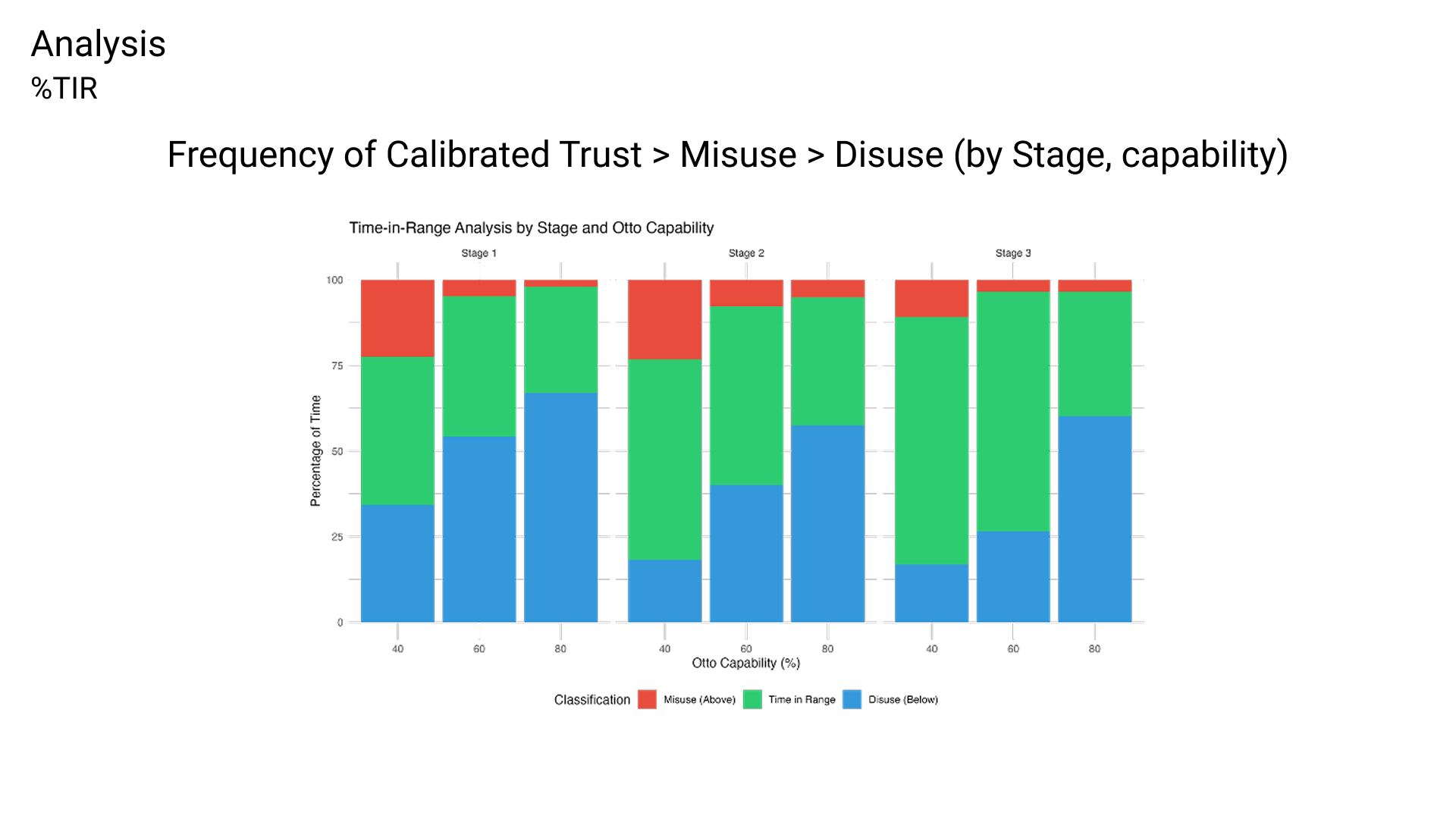
As for the second result, I found that trust calibration can indeed be measured over time. Using a temporal framework, participants were successfully categorized into calibrated, misuse, and disuse groups, introducing a novel quantitative tool for assessing trust dynamics in automation.
Core competencies & reflections
- Research Design: Crafted and executed a counterbalanced multi-block experimental framework involving 189 participants. Independently managed a baseline control condition. Employed multi-method data collection combining survey instruments, behavioral observations, and self-reports.
- Quantitative Analysis: Utilized advanced structural equation modeling in R. Conducted exploratory temporal analyses. Developed correlation and path models incorporating latent variable constructs.
- Tool Development: Collaboratively engineered the Calibratio simulation platform using Unity. Designed an intuitive delegation interface facilitating seamless human-automation collaboration.
- Cross-Disciplinary Integration: Synthesized concepts from cultural psychology, trust theory, automation engineering, AI regulatory frameworks, and cognitive science.
- Technical Writing: Authored an extensive 130+ page thesis featuring clear organization, bespoke visualizations, and an in-depth literature review spanning multiple disciplines.
- Applied Problem-Solving: Translated empirical findings into actionable recommendations aligned with real-world AI regulatory standards such as JAMA CHART guidelines. Proposed practical applications including enhancements to mammography AI deployment.
This was a controlled study with a simple, single-function simulation. Otto sorts shapes. He doesn't drive your car or read your mammogram. The capability levels (40%, 60%, 80%) were deliberately distinct and clearly communicated, which is not how real-world systems behave. And the sample was entirely U.S.-based, which limits how far the cultural findings can stretch. The moral of the story, for me, is that measuring trust and reliance is possible, quantifying calibration is possible, and accounting for who the user is when designing systems is not just nice to have but necessary.
Read the full study on Proquest or Google Docs.
References
Goroza, E. (2025). Quantifying calibration: Bridging trust and reliance in automation across cultural values and dispositional factors [Master's thesis, Tufts University]. ProQuest Dissertations & Theses Global. (Order No. 32238898).
Goroza, E., McCarthy-Bui, G., Zhao, A., Ostenson, E. R., & Miller, D. B. (2025). Quantifying Calibration: Bridging Trust and Reliance in Automation Across Dispositional Factors. Proceedings of the Workshop on Hybrid Automation Experiences (AutomationXP25 at ACM CHI '25, Yokohama, Japan) (Vol. 4101). CEUR-WS.
Parasuraman, R. & Riley, V. (1997). Humans and Automation: Use, Misuse, Disuse, Abuse. Human Factors, 39(2), 230-253.
McKnight, D. H., Carter, M., Thatcher, J. B., & Clay, P. F. (2011). Trust in a Specific Technology: An Investigation of Its Components and Measures. ACM Transactions on Management Information Systems, 2(2), 12.
Hofstede, G. (2001). Culture's Consequences: Comparing Values, Behaviors, Institutions and Organizations Across Nations. Sage Publications.
Razin, Y. S. & Feigh, K. M. (2024). Quantifying Trust in Automation: A Multidimensional Approach. Human Factors.
Skills demonstrated: Experimental design | Structural equation modeling | Survey design | Behavioral simulation | Trust in automation | Cultural psychology | Technical writing | Unity development
Tools used: Unity | R (lavaan) | Qualtrics | Nolop Makerspace
Thesis
M.S. in HFE at Tufts
Contents
Thesis
M.S. in HFE at Tufts
A slide modeled after old Mac computer UI used for a presentation. The text reads: "Automation is everywhere, but are these technologies designed for calibrated use?"
Role
Thesis in partial fulfillment of M.S. in Human Factors Engineering
Dates
February 2024 – August 2025
Organization
Department of Mechanical Engineering, Tufts University
Funding
Wittich Grant (Summer 2024); Trefethen Fellowship (2025)
Advisor
Dave B. Miller, Ph.D.
Committee
Daniel J. Hannon, Ph.D.; Holly Taylor, Ph.D.
Research Title
Quantifying calibration: Bridging trust and reliance in human-automation interaction
Sample
N = 189 adult participants (567 observations)
Recruitment
Prolific platform using stratified sampling by ethnicity
Status
Defended August 2025; published on ProQuest
Overview
For my thesis, I ran a behavioral study (N = 189) to investigate how cultural values and personality traits influence trust and reliance on adaptable automation. I recruited a team of programmers and usability engineers to build a Unity-based behavioral simulation of an adaptable system which I called Otto. This simulation was a game I called Calibratio, a portmanteau of calibration + ratio to reflect the metrics calibrated trust and calibrated use, which are ratio quantities (trust:system capability, use:system capability, respectively) that reflect appropriate use.
The goal of the game was simple: to sort puzzle pieces as they travelled down a conveyor belt track into the correct of three piece categories. The player began with a baseline round to calculate their personalized speed when at 80% accuracy, and then progressed to three gameplay rounds where they could voluntarily delegate workload to their assistant, Otto the robot, in real time, and on a granular scale of 0% to 100%.
Collaborative automation systems like AI, autonomous vehicles, and clinical decision aids are everywhere today, but designing systems for appropriate use is a challenge. Quantitatively speaking, calibrated use is when the level of operator reliance on a machine is equivalent to its actual capabilities.
Today, we often see misuse of technology, like people over-relying on OpenAI's ChatGPT or Tesla's Autopilot, which often results from over-trust in the system. Conversely, disuse occurs when individuals fail to utilize machines that could enhance safety and efficiency.
Because of the trajectory of technological development, the state of collaborative systems will only continue to exacerbate. Automation tools are often designed to boost productivity and keep users engaged, building trust even if the technology itself isn't perfect. Currently, there is a notable gap in understanding how operator dispositional factors such as cultural values and personality traits may enable individuals to over-rely or under-rely on collaborative systems.
Publications & funding
Goroza, E. (2025). Quantifying calibration: Bridging trust and reliance in automation across cultural values and dispositional factors [Master's thesis, Tufts University]. ProQuest Dissertations & Theses Global (Order No. 32238898).
Goroza, E., McCarthy-Bui, G., Zhao, A., Ostenson, E. R., & Miller, D. B. (2025). Quantifying calibration: Bridging trust and reliance in automation across dispositional factors. In CHI '25 Workshop on Hybrid Automation Experiences (AutomationXP25), Yokohama, Japan. CEUR Workshop Proceedings, Vol. 4101.
Wittich Grant — Awarded by the Department of Mechanical Engineering at Tufts University to support graduate student research in engineering.
Trefethen Fellowship Grant — A fellowship provided by Tufts University to support graduate students conducting independent research.
Background & research questions
Problem statement
Collaborative automation systems like AI, autonomous vehicles, and clinical decision aids are everywhere today, but designing systems for appropriate use is a challenge. This idea is an actual term in the Human Factors world, which I sometimes use interchangeably with calibrated use or reliance. Quantitatively speaking, calibrated use is when the level of operator reliance on a machine is equivalent to its actual capabilities.
Today, we often see misuse of technology, like people over-relying on OpenAI's ChatGPT or Tesla's Autopilot, which often results from over-trust in the system. Conversely, disuse occurs when individuals fail to utilize machines that could enhance safety and efficiency. Because of the trajectory of technological development, the state of collaborative systems will only continue to exacerbate.
Currently, there is a notable gap in understanding how operator dispositional factors such as cultural values and personality traits may enable individuals to over-rely or under-rely on collaborative systems. We also lack robust, practical methodologies to accurately assess the appropriateness of user reliance, with respect to system capability. Addressing these problems is an ongoing essential in today's technological climate to maximize safety and technology potential in critical applications.
Literature review
During my literature review, I noticed that a lot of cases labeled as misuse, disuse, or calibrated use are just anecdotal accounts or justified by implication. We don't really have a standard metric of measurement for what is appropriate, what's not, and why. That doesn't really help designers figure out what's effective and what's not.
Another thing I noticed was that operator factors are surprisingly under-researched in human factors studies, despite being crucial to the Human-Machine System. Seminal research highlights the lack of investigation into aspects like culture and personality.
Research Question #1
Can we quantify calibrated use of automation systems?
Research Question #2
How do cultural values and personality traits impact trust in automation?
Design process
Let's Play Calibratio!
I spent much time with my advisor, Dave, on figuring out how to design a simulation of interaction where the task between the automation and the operator was granularizable and parallelizable. In other words, something you could do with the system that can be broken down into measurable quantities, which you both worked on at the same time.
Games are often leveraged in psychology studies, simply because they're fun! Games are perfect little simulation environments for that kind of thing. You incentivize the participants to actually participate by gamifying the task, which motivates them to work towards the desired goal state.
After much debate, we decided on designing a rhythm game kind of like Guitar Hero or Dance Dance Revolution (without all the fancy hardware). These games are great for measuring human performance because the time pressure helps mimic the type of real-world decision-making when engaging with collaborative tasks with automation.
I called the game Calibratio, a portmanteau of calibration and ratio, referring to the ratio of the metrics when calculating calibrated trust/use.
Prototyping, Piloting, and IRB Regulations
Understanding how to figure out the logic of the game algorithms and play involved building several iterations of prototypes of the game. This commenced with building a physical prototype to pilot test with the research team and pilot subjects, which were made of tape to outline the tracks, and stickies as the puzzle pieces, which I swapped out for generic-shaped acrylic resin pieces that I laser-cut.
After deducing some logic from experiencing play in real time and "real life", I then evolved the model into a more sophisticated prototype, which consisted of a wooden track and the actual acrylic resin puzzle pieces that I constructed myself in Nolop, Tufts' makerspace.
Finally, with more insights about the gameplay algorithms and design, it was time to construct the early digital prototypes on Unity, which we would also pilot test to refine into the study version.
Meet Otto, the Automation
Something I struggled with initially was designing the automation itself in the game, which I named Otto. As a thorough researcher who strives for objectivity, I didn't want to design a system riddled with bias in its name, even, much less than the effect of anthropomorphism, tone, or other latent variables which might impact perception. Essentially, I initially tried very hard to find something I realized later was non-existent: an adaptable system in a vacuum.
However, in reality, design is inherently value-laden, meaning that there is no such thing as the pure, "un-tainted" version of Otto I sought for the purposes of examining in this controlled experiment. Thus, I found that the best way to deal with the interference of system qualities was to mitigate all possible factors of Otto apparent to the participant. Otto had no on-screen anthropomorphic embodiment, and only "communicated" with users through text pop-up overlays prior to each game round.
The most salient aspect of Otto's design in my opinion was his transparency in his level of capability. The three gameplay rounds randomized the order of his capability (accuracy at 40%, 60%, or 80%), which he communicated to the player prior to each round.
Measure development
For the "who is the operator" question, I paired the behavioral simulation with a pre-task survey battery on Qualtrics measuring Hofstede's cultural dimensions at the individual level and dispositional trust traits (propensity to trust, confidence in technology). It took me a while to figure out which surveys to select because there’s just so many models of trust in automation. Most people just default to TiA (Jian-Bisantz & Drury, 2000), which is actually flawed because it isn’t necessarily the best tool for the job.
Trust is a multifactorial construct, meaning that it isn't one irreducible measure. In my study, capability-based trust was the main metric of interest because I figured that basing the outcomes on performance was most straightforward in this case. Capability-based trust was measured by querying participants whether they trusted in Otto's reliability (does he get it right?) and Otto's functionality (does he do what I need him to do?).
I chose to base most of my trust questionnaire selection on a model from a recent meta-review by Razin & Feigh (2024). What really stood out to me was how thorough and solid their analysis was. They looked at all kinds of validity and reliability measures, which I thought was a considerably trustworthy analysis method (or was it?). Plus, their meta-review covered different research areas, which I liked because it showed they didn’t limit themselves to just one narrow field. It was refreshing to see an approach that avoids getting stuck in the usual boundaries of a single research domain.
Diagram: Razin & Feigh, 2024.
To measure reliance, I wanted to see how participants actually behaved, with temporal specificity over time. So we built a continuous 0-100% workload knob directly into the game interface. At any point during a round, participants could use the arrow keys to shift how much of the sorting task they delegated to Otto versus kept for themselves. This gave me a near-real-time behavioral trace of reliance as it unfolded, not a post-hoc reconstruction of it.
For dispositional factors, participants took a series of surveys on Qualtrics before playing Calibratio. I chose to look at two categories: culture and personality. To measure culture, I chose Hofstede's five dimensions of cultural values measured at the individual level. To measure personality traits, I captured things like Propensity to Trust and analogous propensities to trust in technology.
Qualtrics Examples
Deployment and IRB Regulation
The next step was deploy the game, where the parent platform for the entire study would be Prolific, which would have the Qualtrics links to the surveys, study ids, participant compensation, and link to the game host.
Deploying the game, however, included finding a suitable platform that was consistent with the Tufts IRB which regulated human subjects studies. With help from the game developers' insights, I landed on hosting the game on a private, password-protected link on the platform itch.io, and used the non-SQL database MongoDB to retrieve data. I sought additional permission from the Tufts Technology Services in order to get this IRB approval.
Analysis & findings
Analysis
I had two big questions going into the analysis. First: do the cultural values and personality traits people bring with them actually predict how they trust and rely on automation? And second: can we put a number on whether someone's use of the system was actually appropriate for what the system could do?
For the first question, I built a three-layer path model made with a structural equation model (SEM). Think of it as a chain. Layer one asks what predicts someone's baseline trust in Otto before they've played. Layer two asks how that baseline trust, combined with Otto's actual capability and how people rated their own performance, shapes trust after playing a round. Layer three asks what ultimately predicts how much of the task people actually handed off to Otto. The whole point was to trace the path from "who you are" to "what you believe" to "what you do."
For the second question, I used a novel analysis technique to quantify time-in-range, which was directly adapted from my experience in diabetes technology research.
Significant findings
The skewed distributions of the participants showed that the cultural sample was not representative of the entire population (US adults).
The cultural factors collectivism and uncertainty avoidance, as well as the traits that expressed how much faith people had in technology were strong predictors of participants' baseline trust in automation prior to any interaction with Otto.
The in-task trust rated right after each round with Otto was strongly predicted by a rating of what the participants thought their own performance, as well as Otto's actual capability. This might've been because his objective statement of reliability was given & usually taken for his word.
The self-rated performance and capability also emerged as significant system factors impacting the third path that identified predictors of reliance. Furthermore, the cultural values Power Distance and Masculinity correlated with participants' delegation. In other words, individuals exhibiting greater acceptance of hierarchical authority (PD) and preferences for assertiveness, material success, and competition over modesty, nurturing, and quality of life (MA) tended to demonstrate increased reliance on Otto.
As for the second result, I found that trust calibration can indeed be measured over time. Using a temporal framework, participants were successfully categorized into calibrated, misuse, and disuse groups, introducing a novel quantitative tool for assessing trust dynamics in automation.
Core competencies & reflections
- Research Design: Crafted and executed a counterbalanced multi-block experimental framework involving 189 participants. Independently managed a baseline control condition. Employed multi-method data collection combining survey instruments, behavioral observations, and self-reports.
- Quantitative Analysis: Utilized advanced structural equation modeling in R. Conducted exploratory temporal analyses. Developed correlation and path models incorporating latent variable constructs.
- Tool Development: Collaboratively engineered the Calibratio simulation platform using Unity. Designed an intuitive delegation interface facilitating seamless human-automation collaboration.
- Cross-Disciplinary Integration: Synthesized concepts from cultural psychology, trust theory, automation engineering, AI regulatory frameworks, and cognitive science.
- Technical Writing: Authored an extensive 130+ page thesis featuring clear organization, bespoke visualizations, and an in-depth literature review spanning multiple disciplines.
- Applied Problem-Solving: Translated empirical findings into actionable recommendations aligned with real-world AI regulatory standards such as JAMA CHART guidelines. Proposed practical applications including enhancements to mammography AI deployment.
This was a controlled study with a simple, single-function simulation. Otto sorts shapes. He doesn't drive your car or read your mammogram. The capability levels (40%, 60%, 80%) were deliberately distinct and clearly communicated, which is not how real-world systems behave. And the sample was entirely U.S.-based, which limits how far the cultural findings can stretch. The moral of the story, for me, is that measuring trust and reliance is possible, quantifying calibration is possible, and accounting for who the user is when designing systems is not just nice to have but necessary.
Read the full study on Proquest or Google Docs.
References
Goroza, E. (2025). Quantifying calibration: Bridging trust and reliance in automation across cultural values and dispositional factors [Master's thesis, Tufts University]. ProQuest Dissertations & Theses Global. (Order No. 32238898).
Goroza, E., McCarthy-Bui, G., Zhao, A., Ostenson, E. R., & Miller, D. B. (2025). Quantifying Calibration: Bridging Trust and Reliance in Automation Across Dispositional Factors. Proceedings of the Workshop on Hybrid Automation Experiences (AutomationXP25 at ACM CHI '25, Yokohama, Japan) (Vol. 4101). CEUR-WS.
Parasuraman, R. & Riley, V. (1997). Humans and Automation: Use, Misuse, Disuse, Abuse. Human Factors, 39(2), 230-253.
McKnight, D. H., Carter, M., Thatcher, J. B., & Clay, P. F. (2011). Trust in a Specific Technology: An Investigation of Its Components and Measures. ACM Transactions on Management Information Systems, 2(2), 12.
Hofstede, G. (2001). Culture's Consequences: Comparing Values, Behaviors, Institutions and Organizations Across Nations. Sage Publications.
Razin, Y. S. & Feigh, K. M. (2024). Quantifying Trust in Automation: A Multidimensional Approach. Human Factors.
Skills demonstrated: Experimental design | Structural equation modeling | Survey design | Behavioral simulation | Trust in automation | Cultural psychology | Technical writing | Unity development
Tools used: Unity | R (lavaan) | Qualtrics | Nolop Makerspace
Thesis
M.S. in HFE at Tufts
Contents
Thesis
M.S. in HFE at Tufts
A slide modeled after old Mac computer UI used for a presentation. The text reads: "Automation is everywhere, but are these technologies designed for calibrated use?"
Role
Thesis in partial fulfillment of M.S. in Human Factors Engineering
Dates
February 2024 – August 2025
Organization
Department of Mechanical Engineering, Tufts University
Funding
Wittich Grant (Summer 2024); Trefethen Fellowship (2025)
Advisor
Dave B. Miller, Ph.D.
Committee
Daniel J. Hannon, Ph.D.; Holly Taylor, Ph.D.
Research Title
Quantifying calibration: Bridging trust and reliance in human-automation interaction
Sample
N = 189 adult participants (567 observations)
Recruitment
Prolific platform using stratified sampling by ethnicity
Status
Defended August 2025; published on ProQuest
Overview
For my thesis, I ran a behavioral study (N = 189) to investigate how cultural values and personality traits influence trust and reliance on adaptable automation. I recruited a team of programmers and usability engineers to build a Unity-based behavioral simulation of an adaptable system which I called Otto. This simulation was a game I called Calibratio, a portmanteau of calibration + ratio to reflect the metrics calibrated trust and calibrated use, which are ratio quantities (trust:system capability, use:system capability, respectively) that reflect appropriate use.
The goal of the game was simple: to sort puzzle pieces as they travelled down a conveyor belt track into the correct of three piece categories. The player began with a baseline round to calculate their personalized speed when at 80% accuracy, and then progressed to three gameplay rounds where they could voluntarily delegate workload to their assistant, Otto the robot, in real time, and on a granular scale of 0% to 100%.
Collaborative automation systems like AI, autonomous vehicles, and clinical decision aids are everywhere today, but designing systems for appropriate use is a challenge. Quantitatively speaking, calibrated use is when the level of operator reliance on a machine is equivalent to its actual capabilities.
Today, we often see misuse of technology, like people over-relying on OpenAI's ChatGPT or Tesla's Autopilot, which often results from over-trust in the system. Conversely, disuse occurs when individuals fail to utilize machines that could enhance safety and efficiency.
Because of the trajectory of technological development, the state of collaborative systems will only continue to exacerbate. Automation tools are often designed to boost productivity and keep users engaged, building trust even if the technology itself isn't perfect. Currently, there is a notable gap in understanding how operator dispositional factors such as cultural values and personality traits may enable individuals to over-rely or under-rely on collaborative systems.
Publications & funding
Goroza, E. (2025). Quantifying calibration: Bridging trust and reliance in automation across cultural values and dispositional factors [Master's thesis, Tufts University]. ProQuest Dissertations & Theses Global (Order No. 32238898).
Goroza, E., McCarthy-Bui, G., Zhao, A., Ostenson, E. R., & Miller, D. B. (2025). Quantifying calibration: Bridging trust and reliance in automation across dispositional factors. In CHI '25 Workshop on Hybrid Automation Experiences (AutomationXP25), Yokohama, Japan. CEUR Workshop Proceedings, Vol. 4101.
Wittich Grant — Awarded by the Department of Mechanical Engineering at Tufts University to support graduate student research in engineering.
Trefethen Fellowship Grant — A fellowship provided by Tufts University to support graduate students conducting independent research.
Background & research questions
Problem statement
Collaborative automation systems like AI, autonomous vehicles, and clinical decision aids are everywhere today, but designing systems for appropriate use is a challenge. This idea is an actual term in the Human Factors world, which I sometimes use interchangeably with calibrated use or reliance. Quantitatively speaking, calibrated use is when the level of operator reliance on a machine is equivalent to its actual capabilities.
Today, we often see misuse of technology, like people over-relying on OpenAI's ChatGPT or Tesla's Autopilot, which often results from over-trust in the system. Conversely, disuse occurs when individuals fail to utilize machines that could enhance safety and efficiency. Because of the trajectory of technological development, the state of collaborative systems will only continue to exacerbate.
Currently, there is a notable gap in understanding how operator dispositional factors such as cultural values and personality traits may enable individuals to over-rely or under-rely on collaborative systems. We also lack robust, practical methodologies to accurately assess the appropriateness of user reliance, with respect to system capability. Addressing these problems is an ongoing essential in today's technological climate to maximize safety and technology potential in critical applications.
Literature review
During my literature review, I noticed that a lot of cases labeled as misuse, disuse, or calibrated use are just anecdotal accounts or justified by implication. We don't really have a standard metric of measurement for what is appropriate, what's not, and why. That doesn't really help designers figure out what's effective and what's not.
Another thing I noticed was that operator factors are surprisingly under-researched in human factors studies, despite being crucial to the Human-Machine System. Seminal research highlights the lack of investigation into aspects like culture and personality.
Research Question #1
Can we quantify calibrated use of automation systems?
Research Question #2
How do cultural values and personality traits impact trust in automation?
Design process
Let's Play Calibratio!
I spent much time with my advisor, Dave, on figuring out how to design a simulation of interaction where the task between the automation and the operator was granularizable and parallelizable. In other words, something you could do with the system that can be broken down into measurable quantities, which you both worked on at the same time.
Games are often leveraged in psychology studies, simply because they're fun! Games are perfect little simulation environments for that kind of thing. You incentivize the participants to actually participate by gamifying the task, which motivates them to work towards the desired goal state.
After much debate, we decided on designing a rhythm game kind of like Guitar Hero or Dance Dance Revolution (without all the fancy hardware). These games are great for measuring human performance because the time pressure helps mimic the type of real-world decision-making when engaging with collaborative tasks with automation.
I called the game Calibratio, a portmanteau of calibration and ratio, referring to the ratio of the metrics when calculating calibrated trust/use.
Prototyping, Piloting, and IRB Regulations
Understanding how to figure out the logic of the game algorithms and play involved building several iterations of prototypes of the game. This commenced with building a physical prototype to pilot test with the research team and pilot subjects, which were made of tape to outline the tracks, and stickies as the puzzle pieces, which I swapped out for generic-shaped acrylic resin pieces that I laser-cut.
After deducing some logic from experiencing play in real time and "real life", I then evolved the model into a more sophisticated prototype, which consisted of a wooden track and the actual acrylic resin puzzle pieces that I constructed myself in Nolop, Tufts' makerspace.
Finally, with more insights about the gameplay algorithms and design, it was time to construct the early digital prototypes on Unity, which we would also pilot test to refine into the study version.
Meet Otto, the Automation
Something I struggled with initially was designing the automation itself in the game, which I named Otto. As a thorough researcher who strives for objectivity, I didn't want to design a system riddled with bias in its name, even, much less than the effect of anthropomorphism, tone, or other latent variables which might impact perception. Essentially, I initially tried very hard to find something I realized later was non-existent: an adaptable system in a vacuum.
However, in reality, design is inherently value-laden, meaning that there is no such thing as the pure, "un-tainted" version of Otto I sought for the purposes of examining in this controlled experiment. Thus, I found that the best way to deal with the interference of system qualities was to mitigate all possible factors of Otto apparent to the participant. Otto had no on-screen anthropomorphic embodiment, and only "communicated" with users through text pop-up overlays prior to each game round.
The most salient aspect of Otto's design in my opinion was his transparency in his level of capability. The three gameplay rounds randomized the order of his capability (accuracy at 40%, 60%, or 80%), which he communicated to the player prior to each round.
Measure development
For the "who is the operator" question, I paired the behavioral simulation with a pre-task survey battery on Qualtrics measuring Hofstede's cultural dimensions at the individual level and dispositional trust traits (propensity to trust, confidence in technology). It took me a while to figure out which surveys to select because there’s just so many models of trust in automation. Most people just default to TiA (Jian-Bisantz & Drury, 2000), which is actually flawed because it isn’t necessarily the best tool for the job.
Trust is a multifactorial construct, meaning that it isn't one irreducible measure. In my study, capability-based trust was the main metric of interest because I figured that basing the outcomes on performance was most straightforward in this case. Capability-based trust was measured by querying participants whether they trusted in Otto's reliability (does he get it right?) and Otto's functionality (does he do what I need him to do?).
I chose to base most of my trust questionnaire selection on a model from a recent meta-review by Razin & Feigh (2024). What really stood out to me was how thorough and solid their analysis was. They looked at all kinds of validity and reliability measures, which I thought was a considerably trustworthy analysis method (or was it?). Plus, their meta-review covered different research areas, which I liked because it showed they didn’t limit themselves to just one narrow field. It was refreshing to see an approach that avoids getting stuck in the usual boundaries of a single research domain.
Diagram: Razin & Feigh, 2024.
To measure reliance, I wanted to see how participants actually behaved, with temporal specificity over time. So we built a continuous 0-100% workload knob directly into the game interface. At any point during a round, participants could use the arrow keys to shift how much of the sorting task they delegated to Otto versus kept for themselves. This gave me a near-real-time behavioral trace of reliance as it unfolded, not a post-hoc reconstruction of it.
For dispositional factors, participants took a series of surveys on Qualtrics before playing Calibratio. I chose to look at two categories: culture and personality. To measure culture, I chose Hofstede's five dimensions of cultural values measured at the individual level. To measure personality traits, I captured things like Propensity to Trust and analogous propensities to trust in technology.
Qualtrics Examples
Deployment and IRB Regulation
The next step was deploy the game, where the parent platform for the entire study would be Prolific, which would have the Qualtrics links to the surveys, study ids, participant compensation, and link to the game host.
Deploying the game, however, included finding a suitable platform that was consistent with the Tufts IRB which regulated human subjects studies. With help from the game developers' insights, I landed on hosting the game on a private, password-protected link on the platform itch.io, and used the non-SQL database MongoDB to retrieve data. I sought additional permission from the Tufts Technology Services in order to get this IRB approval.
Analysis & findings
Analysis
I had two big questions going into the analysis. First: do the cultural values and personality traits people bring with them actually predict how they trust and rely on automation? And second: can we put a number on whether someone's use of the system was actually appropriate for what the system could do?
For the first question, I built a three-layer path model made with a structural equation model (SEM). Think of it as a chain. Layer one asks what predicts someone's baseline trust in Otto before they've played. Layer two asks how that baseline trust, combined with Otto's actual capability and how people rated their own performance, shapes trust after playing a round. Layer three asks what ultimately predicts how much of the task people actually handed off to Otto. The whole point was to trace the path from "who you are" to "what you believe" to "what you do."
For the second question, I used a novel analysis technique to quantify time-in-range, which was directly adapted from my experience in diabetes technology research.
Significant findings
The skewed distributions of the participants showed that the cultural sample was not representative of the entire population (US adults).
The cultural factors collectivism and uncertainty avoidance, as well as the traits that expressed how much faith people had in technology were strong predictors of participants' baseline trust in automation prior to any interaction with Otto.
The in-task trust rated right after each round with Otto was strongly predicted by a rating of what the participants thought their own performance, as well as Otto's actual capability. This might've been because his objective statement of reliability was given & usually taken for his word.
The self-rated performance and capability also emerged as significant system factors impacting the third path that identified predictors of reliance. Furthermore, the cultural values Power Distance and Masculinity correlated with participants' delegation. In other words, individuals exhibiting greater acceptance of hierarchical authority (PD) and preferences for assertiveness, material success, and competition over modesty, nurturing, and quality of life (MA) tended to demonstrate increased reliance on Otto.
As for the second result, I found that trust calibration can indeed be measured over time. Using a temporal framework, participants were successfully categorized into calibrated, misuse, and disuse groups, introducing a novel quantitative tool for assessing trust dynamics in automation.
Core competencies & reflections
- Research Design: Crafted and executed a counterbalanced multi-block experimental framework involving 189 participants. Independently managed a baseline control condition. Employed multi-method data collection combining survey instruments, behavioral observations, and self-reports.
- Quantitative Analysis: Utilized advanced structural equation modeling in R. Conducted exploratory temporal analyses. Developed correlation and path models incorporating latent variable constructs.
- Tool Development: Collaboratively engineered the Calibratio simulation platform using Unity. Designed an intuitive delegation interface facilitating seamless human-automation collaboration.
- Cross-Disciplinary Integration: Synthesized concepts from cultural psychology, trust theory, automation engineering, AI regulatory frameworks, and cognitive science.
- Technical Writing: Authored an extensive 130+ page thesis featuring clear organization, bespoke visualizations, and an in-depth literature review spanning multiple disciplines.
- Applied Problem-Solving: Translated empirical findings into actionable recommendations aligned with real-world AI regulatory standards such as JAMA CHART guidelines. Proposed practical applications including enhancements to mammography AI deployment.
This was a controlled study with a simple, single-function simulation. Otto sorts shapes. He doesn't drive your car or read your mammogram. The capability levels (40%, 60%, 80%) were deliberately distinct and clearly communicated, which is not how real-world systems behave. And the sample was entirely U.S.-based, which limits how far the cultural findings can stretch. The moral of the story, for me, is that measuring trust and reliance is possible, quantifying calibration is possible, and accounting for who the user is when designing systems is not just nice to have but necessary.
Read the full study on Proquest or Google Docs.
References
Goroza, E. (2025). Quantifying calibration: Bridging trust and reliance in automation across cultural values and dispositional factors [Master's thesis, Tufts University]. ProQuest Dissertations & Theses Global. (Order No. 32238898).
Goroza, E., McCarthy-Bui, G., Zhao, A., Ostenson, E. R., & Miller, D. B. (2025). Quantifying Calibration: Bridging Trust and Reliance in Automation Across Dispositional Factors. Proceedings of the Workshop on Hybrid Automation Experiences (AutomationXP25 at ACM CHI '25, Yokohama, Japan) (Vol. 4101). CEUR-WS.
Parasuraman, R. & Riley, V. (1997). Humans and Automation: Use, Misuse, Disuse, Abuse. Human Factors, 39(2), 230-253.
McKnight, D. H., Carter, M., Thatcher, J. B., & Clay, P. F. (2011). Trust in a Specific Technology: An Investigation of Its Components and Measures. ACM Transactions on Management Information Systems, 2(2), 12.
Hofstede, G. (2001). Culture's Consequences: Comparing Values, Behaviors, Institutions and Organizations Across Nations. Sage Publications.
Razin, Y. S. & Feigh, K. M. (2024). Quantifying Trust in Automation: A Multidimensional Approach. Human Factors.
Skills demonstrated: Experimental design | Structural equation modeling | Survey design | Behavioral simulation | Trust in automation | Cultural psychology | Technical writing | Unity development
Tools used: Unity | R (lavaan) | Qualtrics | Nolop Makerspace